What is a Query Builder?
Query Builder is an API that can be used to create search queries in the JAVA content repository. It is extensible tool by which you may add/remove various predicates in a query using this API. The best way to create predicates is by using the Query Builder Debugging Tool: /libs/cq/search/content/querydebug.html. Try to implement your Business use case in the Predicate form using this debugger, Optimize the query, and then implement it in the code.
Query Builder is an API that can be used to create search queries in the JAVA content repository. It is extensible tool by which you may add/remove various predicates in a query using this API. The best way to create predicates is by using the Query Builder Debugging Tool: /libs/cq/search/content/querydebug.html. Try to implement your Business use case in the Predicate form using this debugger, Optimize the query, and then implement it in the code.
Anatomy of a Query:
The query description is a set of predicates that evaluate to an XPATH /JCR query in the backend. To understand more check the screenshot below:
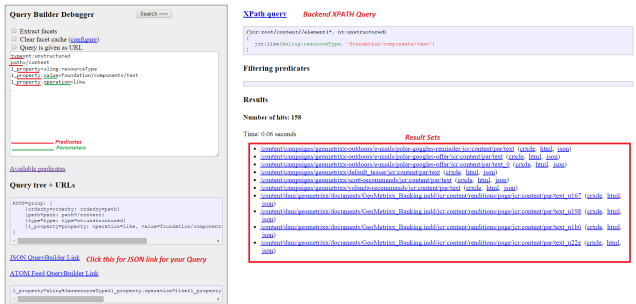
Every Predicate is evaluated using a Predicate Evaluator. There are some in-built predicates in AEM. And you may always customize the predicates and use them as per your Business need. I will go in more detail for creating new predicates later.
The query description is a set of predicates that evaluate to an XPATH /JCR query in the backend. To understand more check the screenshot below:
Every Predicate is evaluated using a Predicate Evaluator. There are some in-built predicates in AEM. And you may always customize the predicates and use them as per your Business need. I will go in more detail for creating new predicates later.
Implementation :
You may refer to the links: Adobe Doc or Use the API to implement your queries using a Query Builder.
You may refer to the links: Adobe Doc or Use the API to implement your queries using a Query Builder.
Standard Predicates: A deep understanding of predicates is necessary if you want to Optimize any if your Search Query.
group.1_daterange.property=jcr:created group.1_daterange.lowerBound=2014-08-18 group.1_daterange.upperBound=2014-08-19
group.2_daterange.property=cq:lastModified group.2_daterange.lowerBound=2014-08-18 group.2_daterange.upperBound=2014-08-19
group.p.or=true
orderBy: This predicate is used to sort the result sets obtained in the query. e.g. orderby=@jcr:score or orderby=@jcr:content/cq:lastModified
orderby.sort: You may define the sorting way for the search results e.g. desc for descending and “” for ascending.
orderby:path: this can also be used to sort by the path.
- path: This is used to search under a particular hierarchy only.
- path.self=true: If true searches the subtree including the main node given in path, if false searches the subtree only.
- path.exact=true: If the true exact path is matched if false all descendants are included.
- path.flat=true: If true searches only the direct children.
- type: It is used for searching for a particular nodetype only.
- property: This is used to search for a specific property only.
- property.value: the property value to the search. Multiple values of a particular property could be given using property.N_value=X, where N is number from 1 to N.
- property.depth: The number of additional levels to search under a node. eg. if property.depth=2 then the property is searched under
- property.and: If multiple properties are present , by default an ORoperator is applied. If you want an AND , you may use property.and=true
- property.operation: “equals” for exact match (default), “unequals” for unequality comparison, “like” for using the jcr:like xpath function , “not” for no match , (value param will be ignored) or “exists” for existence match .(value can be true – property must exist).
- fulltext: It is used to search terms for fulltext search
- fulltext.relPath: the relative path to search in (eg. property or subnode) eg. fulltext.relPath=jcr:content or fulltext.relPath=jcr:content/@cq:tags
- daterange : This predicate is used to search a date property range.
- daterange.property: Specify a property which is searched.
- daterange.lowerBound: Fix a lower bound eg. 2010-07-25
- daterange.lowerOperation : “>” (default) or “>=”
- daterange.upperBound: Fix a lower bound eg. 2013-07-26
- daterange.upperOperation: “<” (default) or “<=”
- relativedaterange: It is an extension of date range that uses relative offsets to server time. It also supports 1s 2m 3h 4d 5w 6M 7y
- relativedaterange.lowerBound: Lower bound offset, default=0
- relativedaterange.upperBound: Upper bound Offset.
- nodename: This is used to search exact nodenames for the result set. It allows few wildcards like: nodename=text* will search for any character or no character after the text. nodename=text? will search for any character after the text.
- tagid: This predicate is used to search for a particular tag on a page. You may specify the exact tagid of a tag in this predicate
- tagid.property: this may be used to specify the path of node where tags are stored.
- group: This predicate is used to create logical conditions in your query. You can create complex conditions using OR & AND operators in different groups. e.g:
group.1_daterange.property=jcr:created group.1_daterange.lowerBound=2014-08-18 group.1_daterange.upperBound=2014-08-19
group.2_daterange.property=cq:lastModified group.2_daterange.lowerBound=2014-08-18 group.2_daterange.upperBound=2014-08-19
group.p.or=true
orderBy: This predicate is used to sort the result sets obtained in the query. e.g. orderby=@jcr:score or orderby=@jcr:content/cq:lastModified
orderby.sort: You may define the sorting way for the search results e.g. desc for descending and “” for ascending.
orderby:path: this can also be used to sort by the path.
Refining the Results: In order to refine the results there are some parameters which could be leveraged:
p.hits=full: Use this when you want to return all the properties in a node. Example
p.hits=selective: Use this if you want to return selective properties in search results. Use this with
p.properties=sling:resourceType jcr:primaryType Example
p.nodedepth: Use this when you need properties of a node and its child nodes in the same search result. Use this with p.hits=full Example
p.facets=true: This will be used to Search Facets based search for the assigned Query. If you want to calculate the count of tags which are present in your search result or you want to know how many templates for a particular page are there etc, you may go with Facets based search. Example
type=cq:Page
orderby=@jcr:score
orderby.sort=desc
1_property=jcr:content/cq:tags
2_property=jcr:content/cq:template
2_property.value=/apps/geometrixx/templates/contentpage
p.facets=true
Use this java code to extract Facets for your search result:
p.hits=full: Use this when you want to return all the properties in a node. Example
p.hits=selective: Use this if you want to return selective properties in search results. Use this with
p.properties=sling:resourceType jcr:primaryType Example
p.nodedepth: Use this when you need properties of a node and its child nodes in the same search result. Use this with p.hits=full Example
p.facets=true: This will be used to Search Facets based search for the assigned Query. If you want to calculate the count of tags which are present in your search result or you want to know how many templates for a particular page are there etc, you may go with Facets based search. Example
type=cq:Page
orderby=@jcr:score
orderby.sort=desc
1_property=jcr:content/cq:tags
2_property=jcr:content/cq:template
2_property.value=/apps/geometrixx/templates/contentpage
p.facets=true
Use this java code to extract Facets for your search result:
Map < String, Facet > facets = result.getFacets();
for (String key: facets.keySet()) {
Facet facet = facets.get(key);
if (facet.getContainsHit()) {
for (Bucket bucket: facet.getBuckets()) {
long count = bucket.getCount();
Map < String, String > params = bucket.getPredicate().getParameters();
for (String k: params.keySet()) {
out.println("<br>k:" + k);
}
}
}
}
- p.limit: Limits the number of search results fetched.
- p.offset: Sets the offset for the search results
- p.guesstotal: The purpose of the p.guessTotal parameter is to return the appropriate number of results that can be shown by combining the minimum viable p.offset and p.limit values.
In most of the cases, the standard predicates would solve your purpose of creating Queries for any business scenario. However, sometimes we may need to Create Custom Predicates. I will tell you more about this later.
Custom Predicate Evaluators:
Broadly there are 2 kinds of Predicate Evaluators which can be used to create new predicates as per Business need.
XPath Predicate: This is used to create a Backend XPATH Query using the new custom predicates which can be defined as per need. Many of the inbuilt CQ predicates are XPATH predicates. Notice that in XPATH Predicate Evaluator the overridden method canXpath() should return true while canFilter() should return false. Use the below code snippet to create Custom Predicates :
import org.apache.felix.scr.annotations.Component;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.day.cq.search.Predicate;
import com.day.cq.search.eval.AbstractPredicateEvaluator;
import com.day.cq.search.eval.EvaluationContext;
/**
* &amp;amp;amp;amp;amp;lt;code&amp;amp;amp;amp;amp;gt;OriginPredicateEvaluator&amp;amp;amp;amp;amp;lt;/code&amp;amp;amp;amp;amp;gt; queries the Livecopy status of a page.
*This property is used to find the Livecopy status of the page.
*origin.value=disconnected gives the XPATH query as jcr:content/@jcr:mixinTypes='cq:LiveSyncCancelled'
*origin.value=locally gives the XPATH query as jcr:content/@jcr:mixinTypes!='cq:LiveSync'
*origin.value=inheritted gives the XPATH query as jcr:content/@jcr:mixinTypes='cq:LiveSync'
* @author hakhan
*/
@Component(metatype = false, factory = "com.day.cq.search.eval.PredicateEvaluator/origin")
public class OriginPredicateEvaluator extends AbstractPredicateEvaluator {
static final String PE_NAME = "origin";
static final String JCRCONTENT_JCRMIXIN = "jcr:content/@jcr:mixinTypes";
static final String PREDICATE_VALUE = "value";
static final String PREDICATE_LIVESYNCCANC = "'cq:LiveSyncCancelled'";
static final String PREDICATE_LIVESYNC = "'cq:LiveSync'";
static final String OP_EQUALS = "=";
static final String OP_NOT_EQUALS = "!=";
private static final Logger logger = LoggerFactory
.getLogger(OriginPredicateEvaluator.class);
@Override
public String getXPathExpression(Predicate predicate,
EvaluationContext context) {
String value = predicate.get(PREDICATE_VALUE);
StringBuilder sb = new StringBuilder();
if(value != null){
if (value.equalsIgnoreCase("inheritted")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_EQUALS);
sb.append(PREDICATE_LIVESYNC);
}
if (value.equalsIgnoreCase("disconnected")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_EQUALS);
sb.append(PREDICATE_LIVESYNCCANC);
}
if (value.equalsIgnoreCase("locally")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_NOT_EQUALS);
sb.append(PREDICATE_LIVESYNC);
}
}
String xpath = sb.toString();
logger.debug("**********XPATH::**********" + xpath);
return xpath;
}
@Override
public boolean canXpath(Predicate predicate, EvaluationContext context) {
return true;
}
@Override
public boolean canFilter(Predicate predicate, EvaluationContext context) {
return false;
}
}
Filter Predicate: This predicate is used whenever you want to Filter out some results which are not needed in the end Search Result. Notice that in Filter Predicate Evaluator the overridden method canXpath() should return false while canFilter() should return true.
import javax.jcr.query.Row;
import org.apache.felix.scr.annotations.Component;
import org.apache.sling.api.resource.Resource;
import org.apache.sling.resource.collection.ResourceCollection;
import com.day.cq.search.Predicate;
@Component(metatype = false, factory = "com.day.cq.search.eval.PredicateEvaluator/samplepredicate")
public class SampleFilterPredicateEvaluator extends AbstractPredicateEvaluator {
public static final String SAMPLE = "samplepredicate";
@Override
public boolean includes(Predicate p, Row row, EvaluationContext context) {
if (!p.hasNonEmptyValue(SAMPLE)) {
return true;
}
/* Write some code logic here as per the condition:
Return true for a favourable Condition for keeping the entity in Search Results.
Return false for an unfavourable Condition for removing the entity from the Search Results.
*/
return false;
}
@Override
public boolean canXpath(Predicate predicate, EvaluationContext context) {
return false;
}
@Override
public boolean canFilter(Predicate predicate, EvaluationContext context) {
return true;
}
}
Improving Search Performance
By far this is the most important question of any project, and I am telling you it's not that difficult. Just a few steps to follow and few things to be aware of and you will be able to optimize the Query to its utmost performance level.
Broadly there are 2 kinds of Predicate Evaluators which can be used to create new predicates as per Business need.
XPath Predicate: This is used to create a Backend XPATH Query using the new custom predicates which can be defined as per need. Many of the inbuilt CQ predicates are XPATH predicates. Notice that in XPATH Predicate Evaluator the overridden method canXpath() should return true while canFilter() should return false. Use the below code snippet to create Custom Predicates :
import org.apache.felix.scr.annotations.Component;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.day.cq.search.Predicate;
import com.day.cq.search.eval.AbstractPredicateEvaluator;
import com.day.cq.search.eval.EvaluationContext;
/**
* &amp;amp;amp;amp;amp;lt;code&amp;amp;amp;amp;amp;gt;OriginPredicateEvaluator&amp;amp;amp;amp;amp;lt;/code&amp;amp;amp;amp;amp;gt; queries the Livecopy status of a page.
*This property is used to find the Livecopy status of the page.
*origin.value=disconnected gives the XPATH query as jcr:content/@jcr:mixinTypes='cq:LiveSyncCancelled'
*origin.value=locally gives the XPATH query as jcr:content/@jcr:mixinTypes!='cq:LiveSync'
*origin.value=inheritted gives the XPATH query as jcr:content/@jcr:mixinTypes='cq:LiveSync'
* @author hakhan
*/
@Component(metatype = false, factory = "com.day.cq.search.eval.PredicateEvaluator/origin")
public class OriginPredicateEvaluator extends AbstractPredicateEvaluator {
static final String PE_NAME = "origin";
static final String JCRCONTENT_JCRMIXIN = "jcr:content/@jcr:mixinTypes";
static final String PREDICATE_VALUE = "value";
static final String PREDICATE_LIVESYNCCANC = "'cq:LiveSyncCancelled'";
static final String PREDICATE_LIVESYNC = "'cq:LiveSync'";
static final String OP_EQUALS = "=";
static final String OP_NOT_EQUALS = "!=";
private static final Logger logger = LoggerFactory
.getLogger(OriginPredicateEvaluator.class);
@Override
public String getXPathExpression(Predicate predicate,
EvaluationContext context) {
String value = predicate.get(PREDICATE_VALUE);
StringBuilder sb = new StringBuilder();
if(value != null){
if (value.equalsIgnoreCase("inheritted")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_EQUALS);
sb.append(PREDICATE_LIVESYNC);
}
if (value.equalsIgnoreCase("disconnected")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_EQUALS);
sb.append(PREDICATE_LIVESYNCCANC);
}
if (value.equalsIgnoreCase("locally")) {
sb.append(JCRCONTENT_JCRMIXIN).append(OP_NOT_EQUALS);
sb.append(PREDICATE_LIVESYNC);
}
}
String xpath = sb.toString();
logger.debug("**********XPATH::**********" + xpath);
return xpath;
}
@Override
public boolean canXpath(Predicate predicate, EvaluationContext context) {
return true;
}
@Override
public boolean canFilter(Predicate predicate, EvaluationContext context) {
return false;
}
}
Filter Predicate: This predicate is used whenever you want to Filter out some results which are not needed in the end Search Result. Notice that in Filter Predicate Evaluator the overridden method canXpath() should return false while canFilter() should return true.
import javax.jcr.query.Row;
import org.apache.felix.scr.annotations.Component;
import org.apache.sling.api.resource.Resource;
import org.apache.sling.resource.collection.ResourceCollection;
import com.day.cq.search.Predicate;
@Component(metatype = false, factory = "com.day.cq.search.eval.PredicateEvaluator/samplepredicate")
public class SampleFilterPredicateEvaluator extends AbstractPredicateEvaluator {
public static final String SAMPLE = "samplepredicate";
@Override
public boolean includes(Predicate p, Row row, EvaluationContext context) {
if (!p.hasNonEmptyValue(SAMPLE)) {
return true;
}
/* Write some code logic here as per the condition:
Return true for a favourable Condition for keeping the entity in Search Results.
Return false for an unfavourable Condition for removing the entity from the Search Results.
*/
return false;
}
@Override
public boolean canXpath(Predicate predicate, EvaluationContext context) {
return false;
}
@Override
public boolean canFilter(Predicate predicate, EvaluationContext context) {
return true;
}
}
Improving Search Performance
By far this is the most important question of any project, and I am telling you it's not that difficult. Just a few steps to follow and few things to be aware of and you will be able to optimize the Query to its utmost performance level.
- Tune your AEM for indexing for appropriate nodes. LINK
- Use the AEM Diagnosis tool for monitoring all queries
- Build a Query with the maximum predicates possible for that node, as long as you reduce the Search pool. e.g. If you are searching for a component node with property= sling:resourceType, add node name predicate too to make the search quicker.
- Keep in consideration what you need in Search Results. If you need cq:Page, it would be a bad idea to search for type=nt:unstructured.
- Always check whether the results are up to the Business need, after the grouping and logic you apply in your Predicate based search.
- Try to reduce the processing of the search results as much as possible. e.g. Its better to use facets then to process the results again
- Go for Custom Predicate Evaluators if you are not able to define your complex query using existing ones or if you think you may simplify the query to a greater level using custom predicates.
- Depending on your application logic, if the result set is more, don't load all the results in DOM and go via partial load using p.limit and p.offset parameters.
- If the search is for anonymous users and no permission sensitive search is needed, use p.guesstotal=true. The purpose of the p.guessTotal parameter is to return the appropriate number of results that can be shown by combining the minimum viable p.offset and p.limit values. Basically, it stops the permission check for that session on each node of the result set and makes the Search query performance better.
References:
https://docs.adobe.com/docs/en/aem/6-1/develop/search/querybuilder-api.html
http://www.slideshare.net/alexkli/cq5-querybuilder-adapttoberlin-2011
http://cq-ops.tumblr.com/post/23543240500/how-to-use-cqs-query-debugger-tool
http://tech.ethomasjoseph.com/2015/03/tuning-your-jcr-queries-for-aem.html
http://aemcq5.blogspot.in/2014/11/cq5-querybuilder-simplified.html
https://docs.adobe.com/docs/en/aem/6-1/develop/search/querybuilder-api.html
http://www.slideshare.net/alexkli/cq5-querybuilder-adapttoberlin-2011
http://cq-ops.tumblr.com/post/23543240500/how-to-use-cqs-query-debugger-tool
http://tech.ethomasjoseph.com/2015/03/tuning-your-jcr-queries-for-aem.html
http://aemcq5.blogspot.in/2014/11/cq5-querybuilder-simplified.html

No comments:
Post a Comment
If you have any doubts or questions, please let us know.