This revolutionary way of storing data for content in a hierarchical manner to enable versioning and performance allowed many diverse enterprise-level CMS including Jahia, Hippo CMS, Magnolia CMS, Oracle Beehive, and Alfresco, to name a few.
Content Repository Extreme (CRX) is Day Software version of the implementation of JCR specification that borrowed heavily from Apache Jackrabbit but continued to add other powerful open-source Java technologies like Apache Felix that implements OSGi specification to ease the feature deployment management, and accessible through Apache Sling (also developed by Day Software), a REST-based web framework, making it fully web compatible.

In addition to aforementioned powerful Java technologies to create one-of-a-kind WCMS, CRX, through Jackrabbit, uses Apache Lucene to index content and make the content available for searching. Needless to say, Lucene is yet another powerful open-source Java technology that enables powerful indexing and search. For this article, we will particularly focus on its analyzer capability.
If you are like me, new to AEM CQ5, and needing to enable stemming for search that allows searching “hike” that would allow matches “hikes“, “hiked“, and “hiking“, you will soon be lost due to incorrect instruction and an example provided by Adobe documentation. Googling “CQ5 search stemming” quickly returns the Adobe help page that shows how easy it is to add stemming capability to search: by adding tilde (~) at the end of the search query:
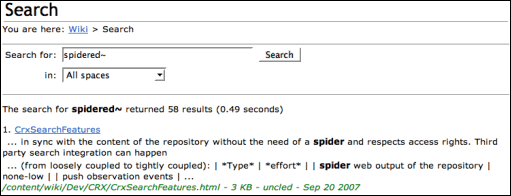
I too was very happy to see the search results returning more than just the exact match. But soon, you will discover that something was wrong. The search also returned similar sounding words like “like“, “kite“. This is when I looked further into the underlying technology, Lucene, and its documentation to see what is going on.
Turned out that, in Lucene, adding tilde enabled fuzzy search, which is a powerful search capability, but it wasn’t stemming. This was the perfect reason why search “hike” returned “like”, since its default fuzzy search distance is 0.5, the trailing “ke” made this match possible. In fact, when you search stemming”, the page returns no result. This made me ponder. It’s got to be in Lucene that indexes and enables stemming search. Further research revealed that Lucene implemented analyzers to not only enable more concise indexing and searching for English, but there are analyzers for most of major languages, including Hebrew, Korea, Chinese, Japanese, Russian, Thai, and Arabic. It was clear that somehow CRX was set to StandardAnalyzer and that enabling EnglishAnalyzer should allow stemming.
Since CRX meant sorting through a maze of Java technologies, it made sense to actually try out the version of Lucene that shipped with AEM CQ 5.6.1. According to this post, I soon found out that the Lucene core JAR file was under author\crx-quickstart\launchpad\felix\bundle65\version0.0\bundle.jar, and that it shipped version 3.6.0 with analyzer library that had EnglishAnalyzer library.
Following this great Lucene tutorial, I was able to quickly setup my own test, and confirm that indeed EnglishAnalyzer allowed indexing words with stemming. Though, one interesting snag I ran into was that the search term has to be the root word and cannot be the variation. Searching “hike” returned “hiking” but searching “hiking” did not return “hike”. This meant that the search words has to be in the root form. This made sense because when Lucene indexes words with EnglishAnalyzer, it would store root form, not the variation, to enable stemming search.
Download Source Code from GitHub
With the renewed discovery, the next step was to find out how to enable EnglishAnalyzer on AEM CQ5.6.1. Many documentation showed that CRX implemented Jackrabbit, but they all pointed out how to include index_configuration.xml to configure the indexer and not about setting the analyzer. After many many hours of researching, I ran across a post that was trying to configure Lucene for their own CMS. It showed that all you needed to specify an analyzer was to add it as an <param> under <SearchIndex>. For AEM CQ5, workspace.xml is found in author\crx-quickstart\repository\workspaces\crx.default folder. Edit workspace.xml and add the highlighted line:
<SearchIndex class="com.day.crx.query.lucene.LuceneHandler"> <param name="path" value="${wsp.home}/index"/> <param name="resultFetchSize" value="50"/> <param name="analyzer" value="org.apache.lucene.analysis.en.EnglishAnalyzer"/> </SearchIndex>
<SearchIndex class="com.day.crx.query.lucene.LuceneHandler">
<param name="path" value="${wsp.home}/index"/>
<param name="resultFetchSize" value="50"/>
<param name="analyzer" value="org.apache.lucene.analysis.en.EnglishAnalyzer"/>
</SearchIndex>
Apply this to both authors and publish instances and restart AEM CQ5.
That’s it! As long as you are doing a fulltext search within the Query, the results will return all matches based on stemming:
public List<Hit> getHits(QueryBuilder queryBuilder, Session session, String path, String escapedQuery){
Map mapFullText = new HashMap();
mapFullText.put("path",path);
mapFullText.put("fulltext", escapedQuery);
mapFullText.put("fulltext.relPath", "jcr:content"); mapFullText.put("type","nt:hierarchyNode" ); mapFullText.put("boolproperty","jcr:content/hideInNav"); mapFullText.put("boolproperty.value","false");
mapFullText.put("p.limit","-1"); mapFullText.put("orderby","@jcr:content/cq:lastModified"); // order by latest first (pbae) mapFullText.put("orderby.sort", "desc");
PredicateGroup pg=PredicateGroup.create(mapFullText);
Query query = queryBuilder.createQuery(pg,session); query.setExcerpt(true);
return query.getResult().getHits();
}
public List<Hit> getHits(QueryBuilder queryBuilder, Session session, String path, String escapedQuery){
Map mapFullText = new HashMap();
mapFullText.put("path",path);
mapFullText.put("fulltext", escapedQuery);
mapFullText.put("fulltext.relPath", "jcr:content");
mapFullText.put("type","nt:hierarchyNode" );
mapFullText.put("boolproperty","jcr:content/hideInNav");
mapFullText.put("boolproperty.value","false");
mapFullText.put("p.limit","-1");
mapFullText.put("orderby","@jcr:content/cq:lastModified"); // order by latest first (pbae)
mapFullText.put("orderby.sort", "desc");
PredicateGroup pg=PredicateGroup.create(mapFullText);
Query query = queryBuilder.createQuery(pg,session);
query.setExcerpt(true);
return query.getResult().getHits();
}
One interesting finding is that even though the index was not rebuilt using EnglishAnalyzer, it seems that index was already indexed with the stemming on as if AEM CQ5 knew that my instance is by default on English and somehow used the proper analyzer. This made the job all the more easier since I did not have to reindex the whole repository that could take hours to complete.
public List<Hit> getHits(QueryBuilder queryBuilder, Session session, String path, String escapedQuery){
Map mapFullText = new HashMap();
mapFullText.put("path",path);
mapFullText.put("fulltext", escapedQuery);
mapFullText.put("fulltext.relPath", "jcr:content");
mapFullText.put("type","nt:hierarchyNode" );
mapFullText.put("boolproperty","jcr:content/hideInNav");
mapFullText.put("boolproperty.value","false");
mapFullText.put("p.limit","-1");
mapFullText.put("orderby","@jcr:content/cq:lastModified"); // order by latest first (pbae)
mapFullText.put("orderby.sort", "desc");
PredicateGroup pg=PredicateGroup.create(mapFullText);
Query query = queryBuilder.createQuery(pg,session);
query.setExcerpt(true);
return query.getResult().getHits();
}
One interesting finding is that even though the index was not rebuilt using EnglishAnalyzer, it seems that index was already indexed with the stemming on as if AEM CQ5 knew that my instance is by default on English and somehow used the proper analyzer. This made the job all the more easier since I did not have to reindex the whole repository that could take hours to complete.

No comments:
Post a Comment
If you have any doubts or questions, please let us know.